Showing
- CMakeModules/Findflann.cmake 0 additions, 14 deletionsCMakeModules/Findflann.cmake
- CMakeModules/Findtinyxml.cmake 0 additions, 21 deletionsCMakeModules/Findtinyxml.cmake
- INSTALL 0 additions, 32 deletionsINSTALL
- LICENSE 34 additions, 0 deletionsLICENSE
- README.md 203 additions, 148 deletionsREADME.md
- cmake 1 addition, 0 deletionscmake
- colcon.pkg 6 additions, 0 deletionscolcon.pkg
- development/build.md 17 additions, 0 deletionsdevelopment/build.md
- development/release.md 34 additions, 0 deletionsdevelopment/release.md
- development/scripts/pixi/activation.bat 13 additions, 0 deletionsdevelopment/scripts/pixi/activation.bat
- development/scripts/pixi/activation.sh 37 additions, 0 deletionsdevelopment/scripts/pixi/activation.sh
- development/scripts/pixi/activation_clang.sh 5 additions, 0 deletionsdevelopment/scripts/pixi/activation_clang.sh
- development/scripts/pixi/activation_clang_cl.bat 3 additions, 0 deletionsdevelopment/scripts/pixi/activation_clang_cl.bat
- doc/CMakeLists.txt 19 additions, 0 deletionsdoc/CMakeLists.txt
- doc/Doxyfile.extra.in 1 addition, 0 deletionsdoc/Doxyfile.extra.in
- doc/distance_computation.png 0 additions, 0 deletionsdoc/distance_computation.png
- doc/generate_distance_plot.py 67 additions, 0 deletionsdoc/generate_distance_plot.py
- doc/gjk.py 661 additions, 0 deletionsdoc/gjk.py
- doc/images/coal-performances.jpg 0 additions, 0 deletionsdoc/images/coal-performances.jpg
- doc/images/coal-vs-the-rest-of-the-world.pdf 0 additions, 0 deletionsdoc/images/coal-vs-the-rest-of-the-world.pdf
CMakeModules/Findflann.cmake
deleted
100644 → 0
CMakeModules/Findtinyxml.cmake
deleted
100644 → 0
INSTALL
deleted
100644 → 0
LICENSE
0 → 100644
This diff is collapsed.
colcon.pkg
0 → 100644
development/build.md
0 → 100644
development/release.md
0 → 100644
development/scripts/pixi/activation.bat
0 → 100644
development/scripts/pixi/activation.sh
0 → 100644
development/scripts/pixi/activation_clang.sh
0 → 100644
doc/CMakeLists.txt
0 → 100644
doc/Doxyfile.extra.in
0 → 100644
doc/distance_computation.png
0 → 100644
{kind=link}

36.9 KiB
doc/generate_distance_plot.py
0 → 100644
doc/gjk.py
0 → 100644
doc/images/coal-performances.jpg
0 → 100644
{kind=link}
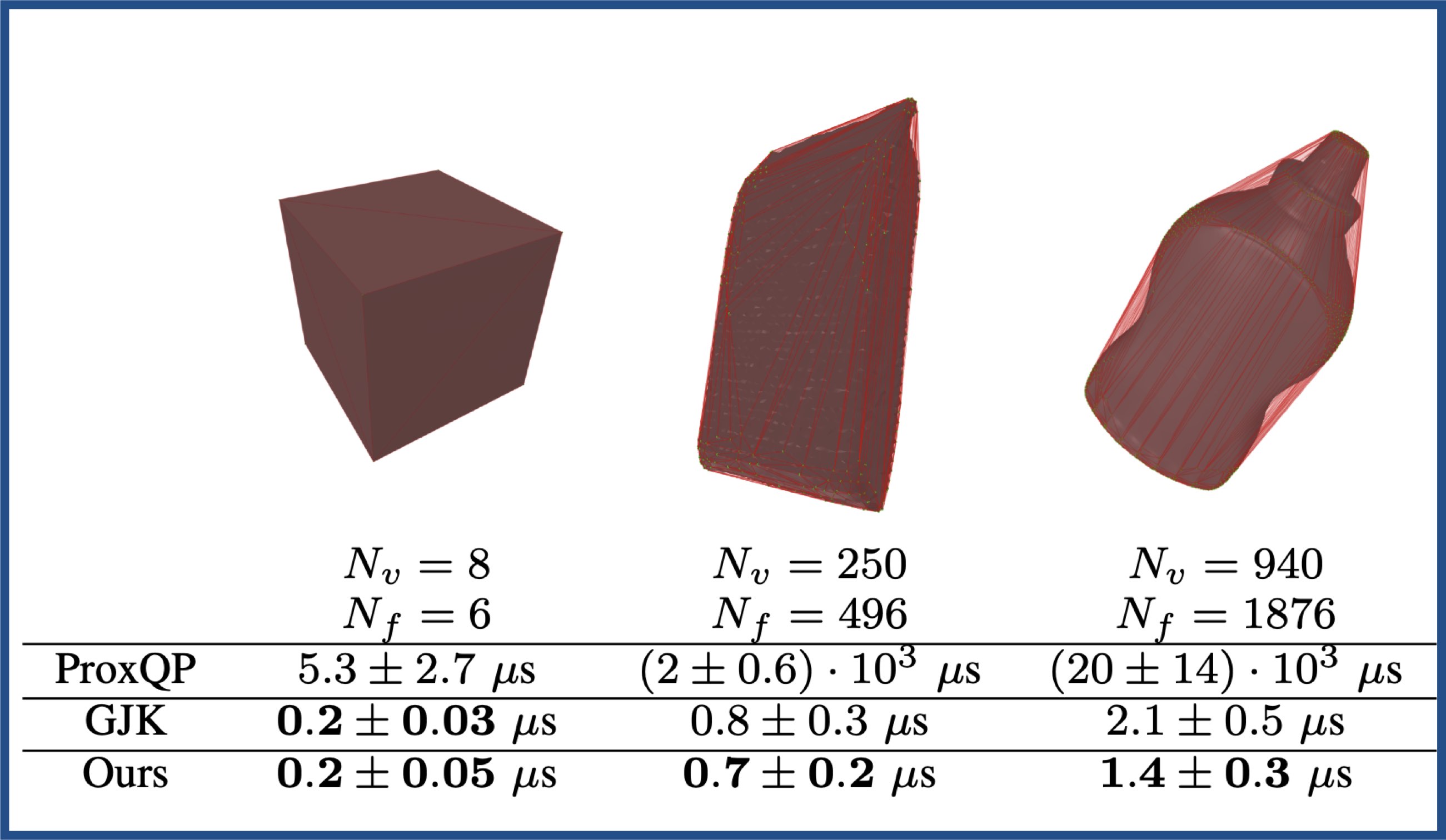
285 KiB
doc/images/coal-vs-the-rest-of-the-world.pdf
0 → 100644
File added